






背景
公司内有一个2期系统,采用的Shiro权限框架,与1期的sso服务做了单点登录。 1期采用了Shiro CAS框架。
随着业务发展,我们把单点系统单独拿出来,重做了一个账号平台, 可以方便接入各种账号。新的应用直接接入的账号平台, 而很多老的应用(有一些是外包出去的)依旧接入的1期sso。
所以,在新的账号平台上线后,就开始对1期sso服务进行改造,以集成到新账号平台。
故障
- 2021-04-22 08:35 接到运维电话, 告知我2期无法登陆。 此时我正在上班路上, 电话告知郝昕一些简单的排查方法。随后又接到其他反馈电话。
- 2021-04-22 09:00 我赶到公司,开始漫长的排错之旅。
这里插入一张2期登录的时序图。
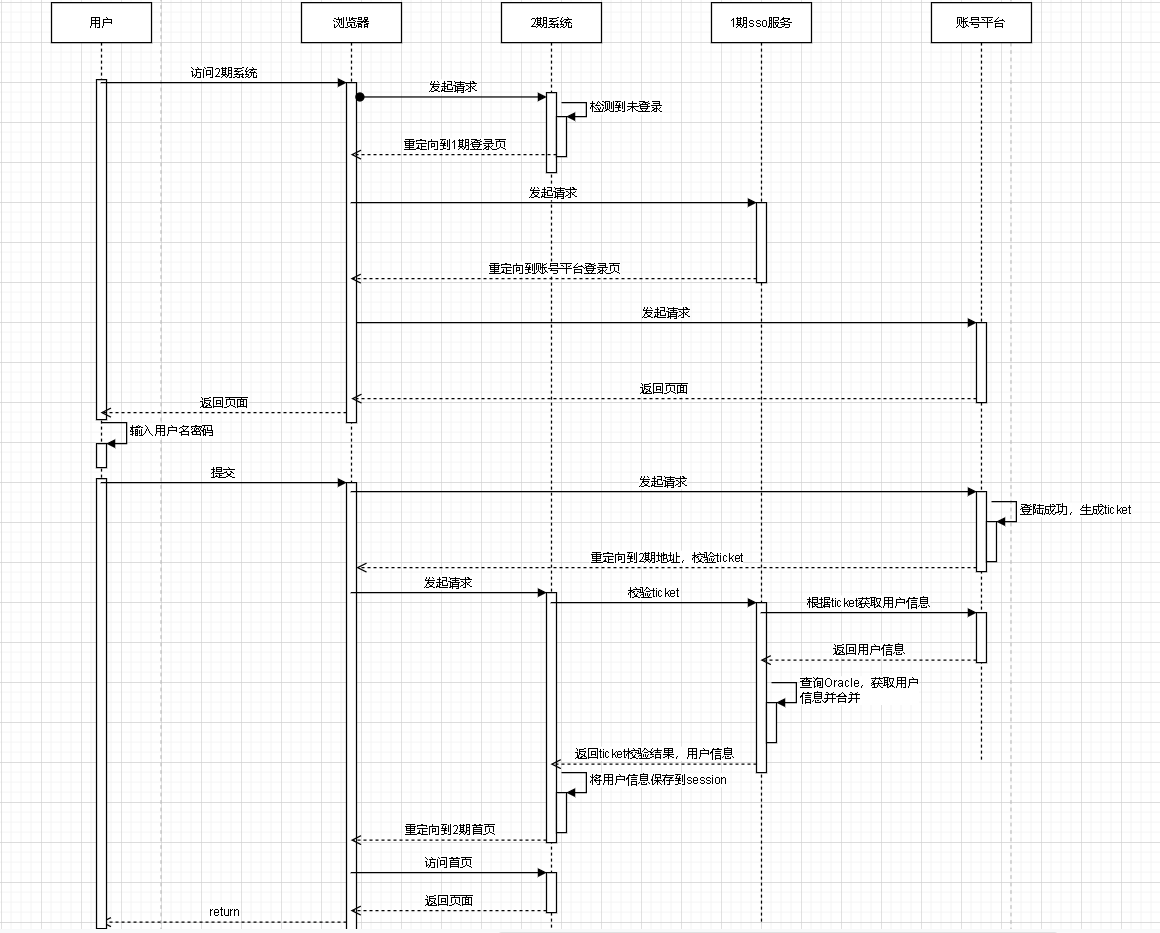
2期采用的shiro框架,1期sso采用的shiro CAS框架
先入为主的思想,我以为是账号平台发生了问题, 在查看账号平台服务日志后,确认账号服务没问题,单独访问账号平台是正常的, 排除账号平台的问题。
这时我又重新审视了一遍问题,根据故障现象,判断是无法访问2期系统导致。 于是查看2期日志,发现是linux句柄数不足导致系统无法访问:
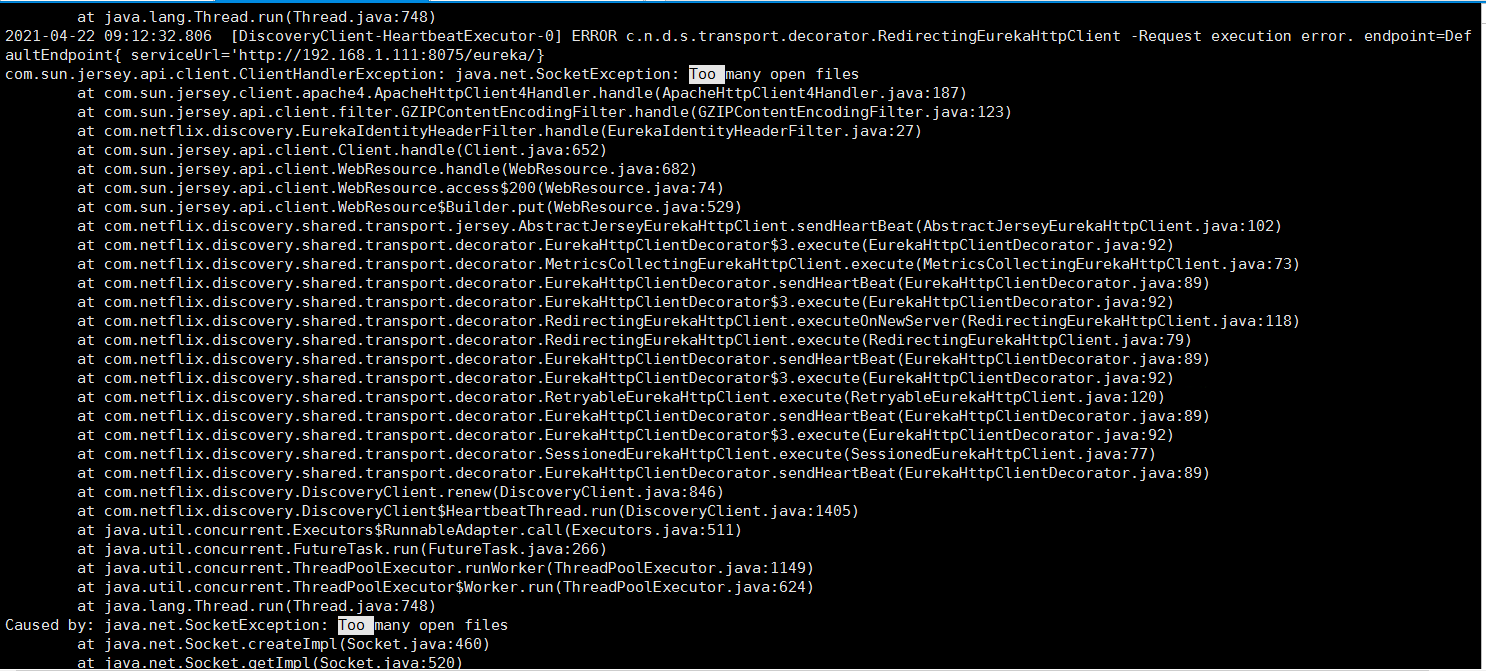
故障初步解决
这里解释一下, 在linux中,所有事物都是文件,比如我们的2期服务为例:
* 它打开的日志文件算一个文件句柄
* 它打开的数据库连接算一个文件句柄
* 它打开的redis连接算一个文件句柄
* 外部访问到2期服务,占用的tcp连接算一个文件句柄
...
总之, 与进程相关的一切事物,都认为是文件。通过命令 ulimit -a 可以查看句柄数量:
[root@ecs1114 ~]# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 256991
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 256991
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
可以看到, linux默认的,每个进程的句柄数是1024, 超过1024后就会报错:Too many open files。
可以通过命令 lsof | grep PID 来查看进程占用的句柄数:
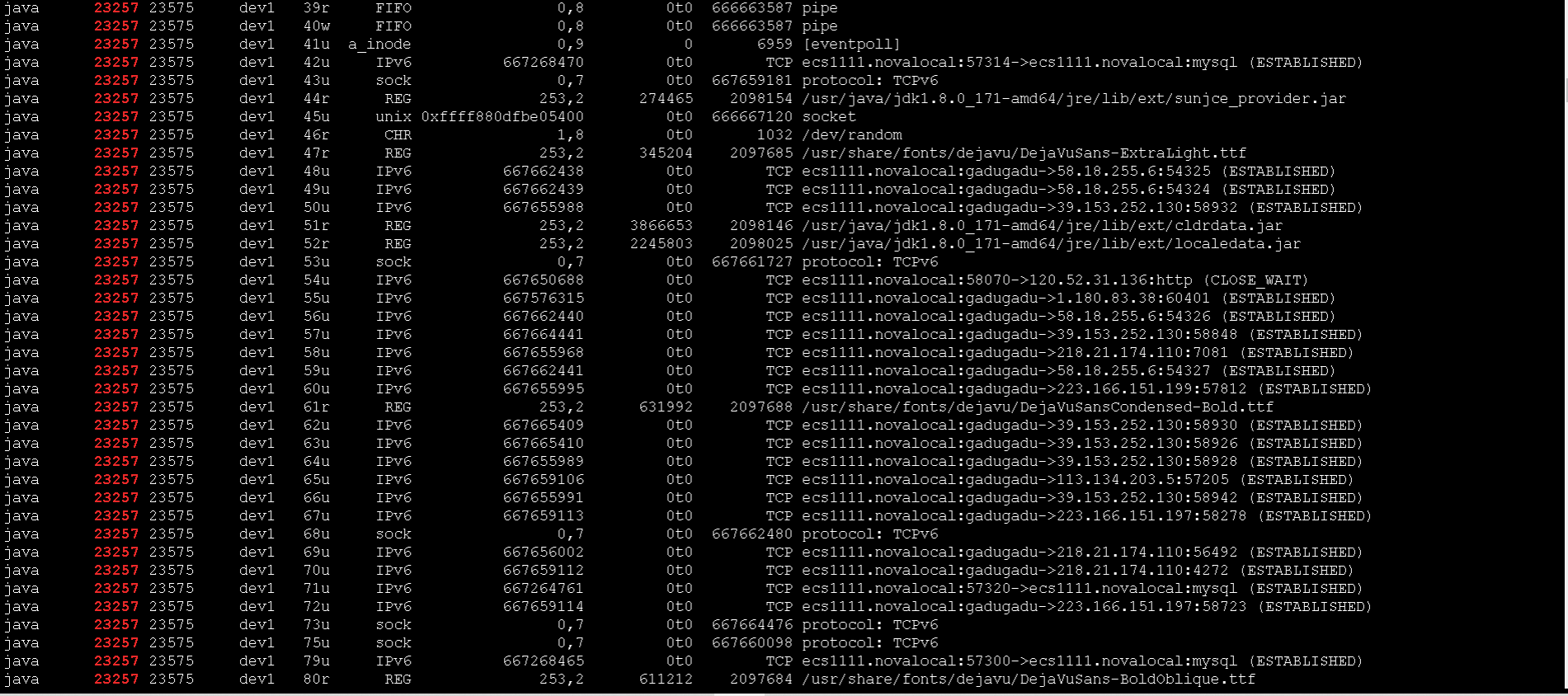
找到问题之后, 解决起来就简单了, 网上有很多这种资料。
解决方案
- 首先, 使用命令
ulimit –n 65535临时修改进程默认的句柄数。重启后该配置会重置。 - 修改文件
/etc/security/limits.conf, 增加两行:
* soft nofile 2000
* hard nofile 2000
- 重启进程。
改完之后, 就不会再出现 Too many open files 错误了。
Too Young Too Simple
这一系列骚操作走完之后,以为问题就解决了。 再次访问2期系统,发现能正常跳转到登录页面, 输入用户名、密码,提交之后就开始了漫长的等待...
此时,我已经陷入惯性思维了, 怀疑是账号服务也出现了Too many open files错误, 连日志都没看,不管3*7=21直接把账号服务重启了。 然后发现问题依旧。 打开浏览器调试工具,发现卡在了2期服务校验ticket的接口上。
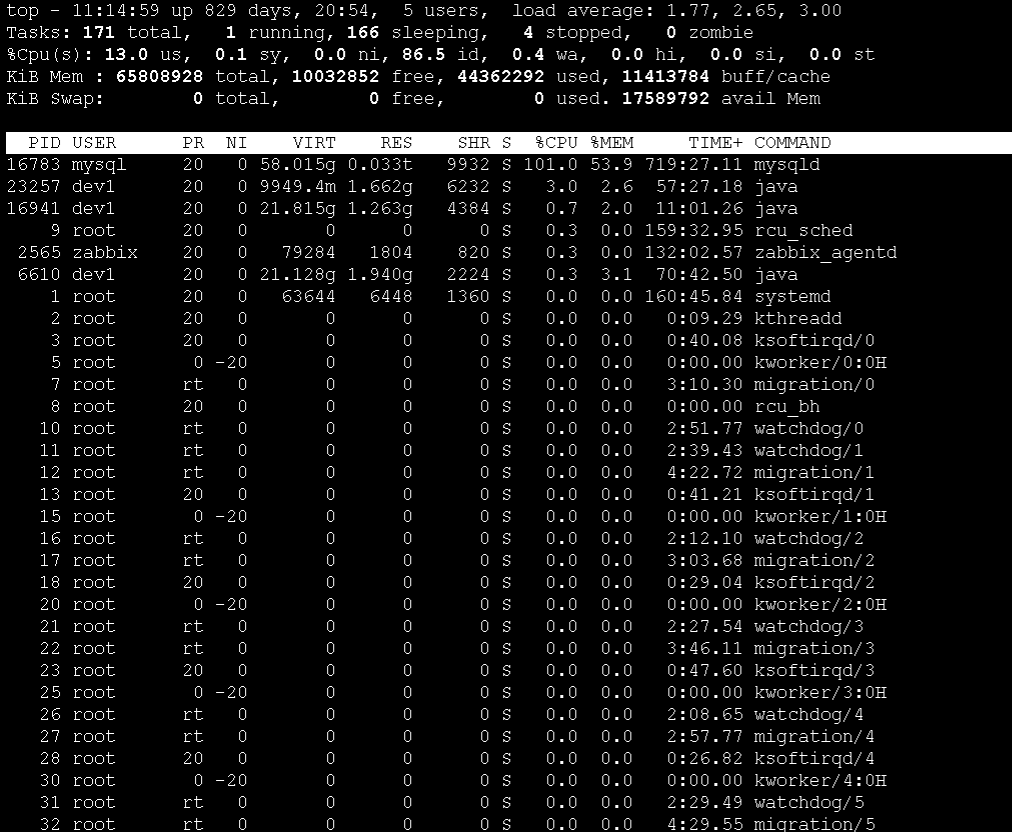
在经过数次重启2期服务之后, 我开始怀疑是服务器的问题, 通过top命令,我发现服务load在3-5左右。虽然高,但是也不会让服务不响应。(下图是top示例,非当时的top数值)
排除负载问题后,我又查看了2期服务的日志, 没发现任何异常,但是请求就是被挂起。 此时我还是怀疑服务器的问题, 在排除 磁盘满、磁盘IO太大、内存、流量打满等问题之后, 已经可以确定服务器虽然负载高,但还正常工作。
这个时候我开始怀疑是2期服务GC导致请求被挂起, 于是使用jstat命令查看GC情况:
[root@ecs1111 ~]# jstat -gcutil 23257 3000
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 2.01 3.34 10.90 93.06 90.02 3911 45.978 6 0.191 46.169
0.00 2.01 7.28 10.90 93.06 90.02 3911 45.978 6 0.191 46.169
0.00 2.01 12.35 10.90 93.06 90.02 3911 45.978 6 0.191 46.169
0.00 2.01 15.98 10.90 93.06 90.02 3911 45.978 6 0.191 46.169
0.00 2.01 15.99 10.90 93.06 90.02 3911 45.978 6 0.191 46.169
发现GC也正常。
至此,所有线索都断了。最后实在没办法,只能再看2期日志,这时候发现已经有异常抛出来了,总算又有了线索:
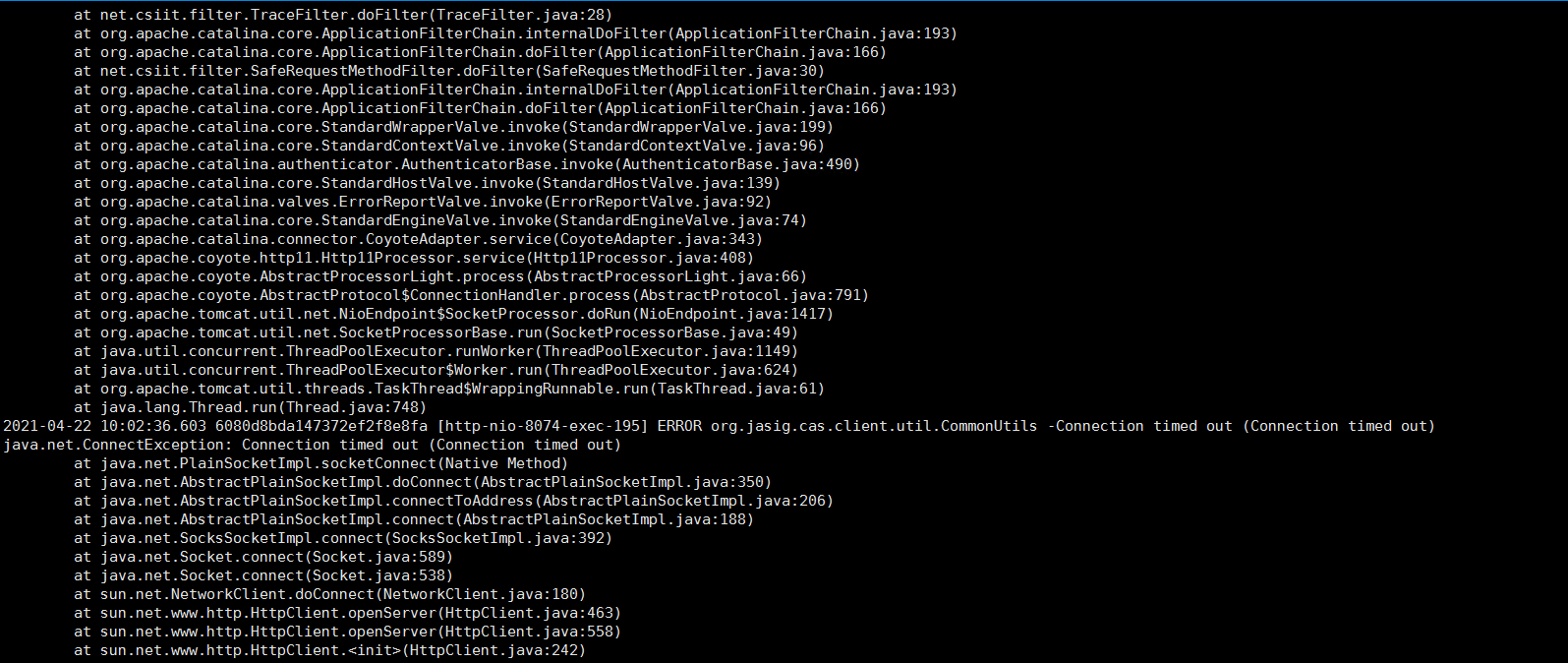
根据堆栈信息,确定是1期sso服务,在校验ticket的时候超时了。 然后去看了1期的日志,发现有个SQL报错:
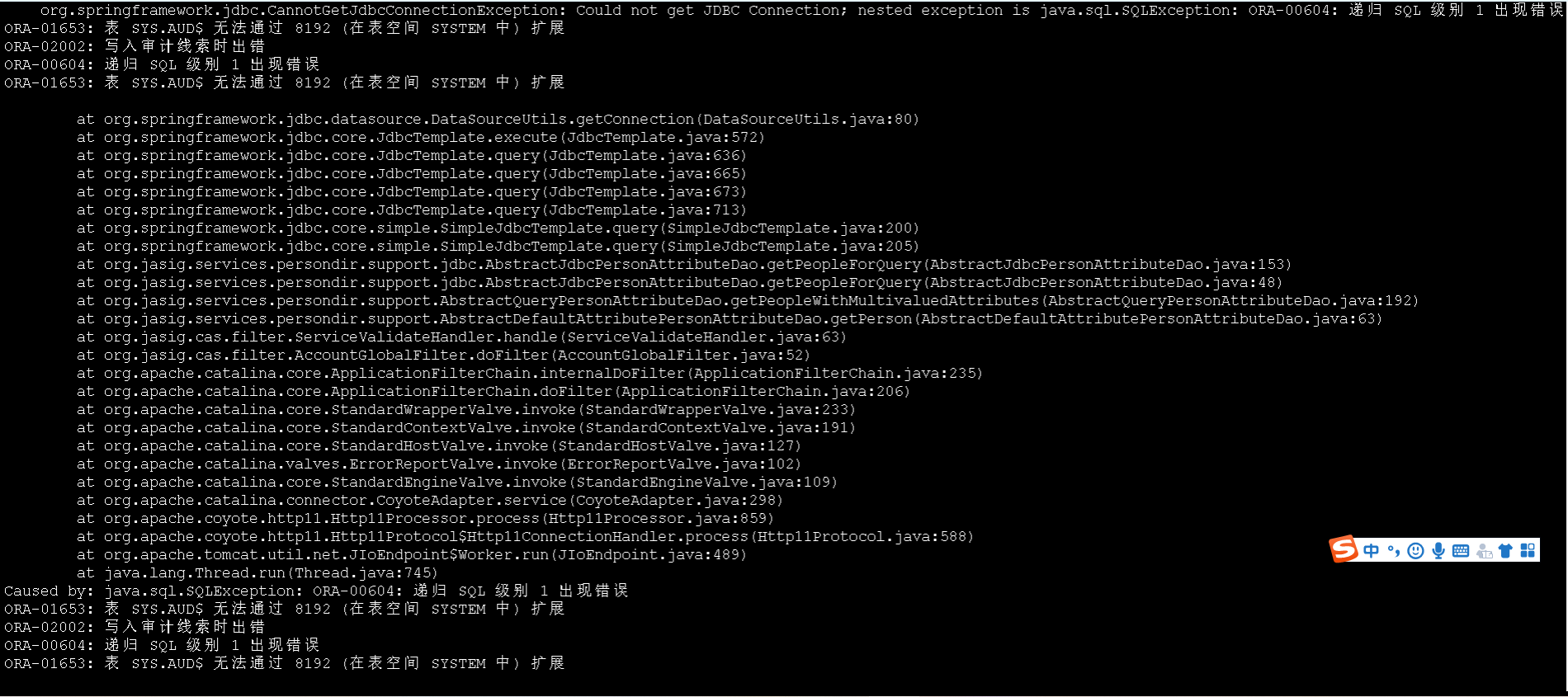
我看到这个错误之后, 只是意识到Oracle表空间满了,按照以往的经验,这个报错是极快的,不会导致超时问题。 根据2期和1期sso服务以及账号平台的时序图,我再次怀疑是账号平台的接口慢,导致了超时...
在经历了N种手段排除了账号平台的嫌疑之后,我已经不知道该往哪个方向排查了。 此时唯一确定的就是1期sso服务,校验ticket接口超时。 没办法又打开1期代码, 然后在1期sso服务的机器上面装了arthas工具,逐步排查,终于发现罪魁祸首就是Oracle!
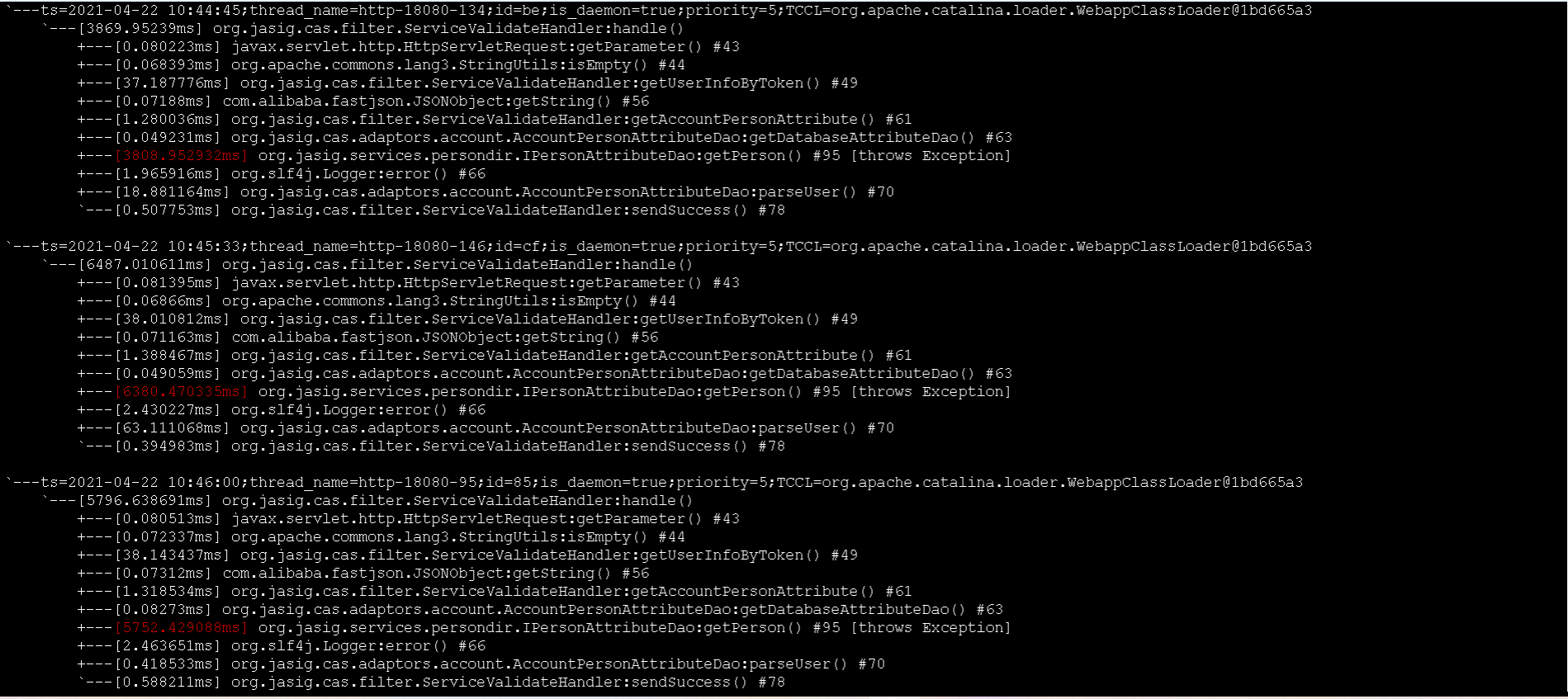
而这个时候已经11点了,距离问题暴露出来已经2.5小时! 联系运维给Oracle扩容之后, 问题终于解决。
经验及改进
经验
- 排错过程中,不能放过任何一个可疑的点
- 多看日志,绝大部分错误会在日志中露出蛛丝马迹
- 对系统结构要很清晰
改进
- 2期系统登录时,直连账号平台,跳过1期sso服务。减少调用路径
- 2期系统、1期sso服务、账号平台 要纳入监控
Q.E.D.